Patrick Wieschollek
Mathematics & Machine Learning PhD | Senior Applied Scientist at Amazon
Advanced Autonomous Robotics R&D / Real-Time Computer Vision / MLOps and CI/CD for Robotics / AWS Cloud
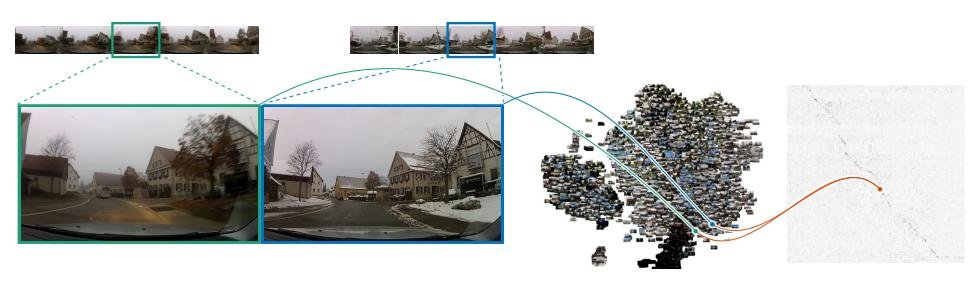
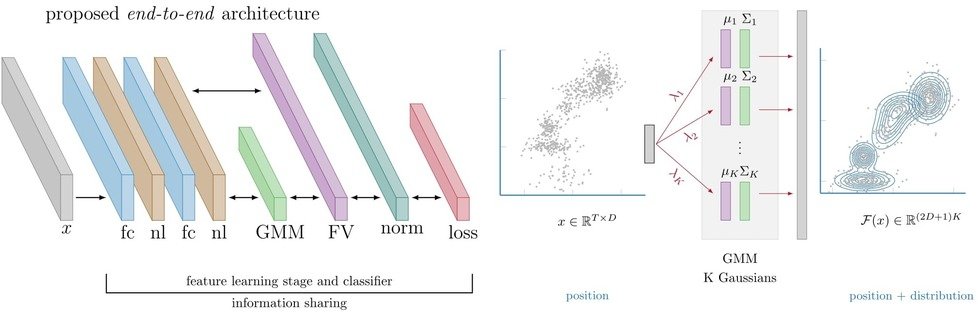
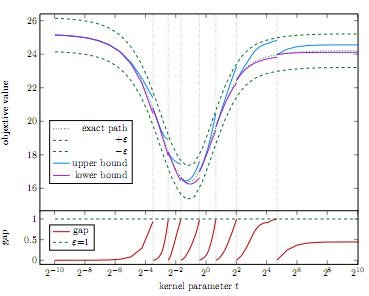
As an Autonomous Navigation & Perception Specialist at Amazon, I focused on developing core, next-generation functionalities for Amazon's advanced robotic and autonomous systems. My expertise spans the full development cycle, from developing state-of-the-art algorithms, optimizing them for embedded systems up to scalable cloud infrastructure.